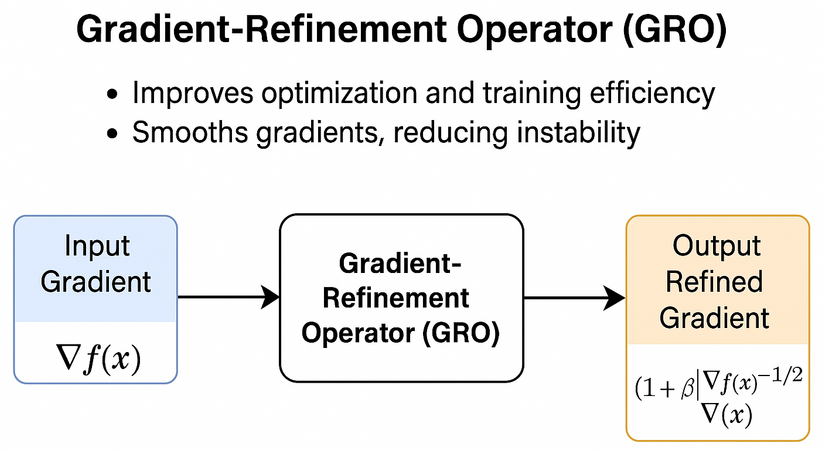
Why the Gradient-Refinement Operator (GRO) Matters
Training machine learning models involves adjusting parameters in the direction of the gradient—a vector that tells the model how to improve. But in real-world scenarios, these gradients often become unstable, especially in high-dimensional or noisy environments. Sudden spikes in gradient magnitude can lead to erratic updates, slow learning, or even complete training failure. The Gradient-Refinement Operator (GRO) offers an elegant solution. It dynamically scales the gradient based on its own size: Small gradients remain mostly unchanged. Large gradients are automatically dampened. This intelligent refinement process ensures:
More stable learning, by smoothing out dangerous spikes without losing direction.
Faster convergence, helping the model reach optimal performance more efficiently.
Increased robustness, especially in deep learning, reinforcement learning, and other sensitive optimization tasks.
Unlike manual tricks like gradient clipping or adaptive learning rates, GRO provides a mathematically grounded, continuous adjustment that preserves the integrity of the learning signal. Whether you’re building AI for finance, healthcare, robotics, or language models—GRO adds stability, precision, and resilience to your training pipeline.