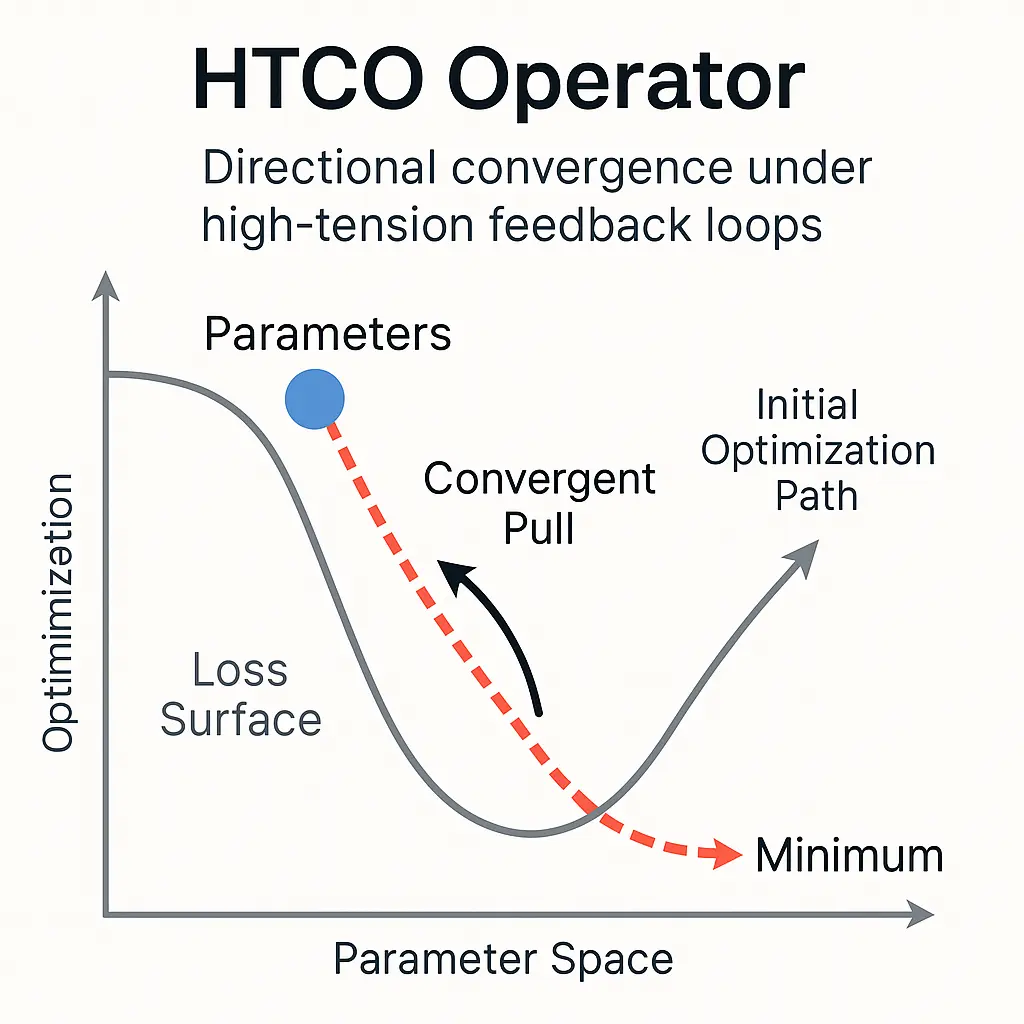
The HTCO operator is designed for situations where optimization landscapes are highly irregular, fragile, or prone to chaotic gradient behavior—such as in unstable training regimes or adversarial learning settings. It’s particularly useful in:
Deep learning tasks suffering from gradient noise or oscillations
Meta-learning and few-shot learning under volatile parameter updates
Quantum-inspired models requiring energy convergence under dynamic constraints
Scenarios where models “hover” near a solution but fail to stabilize
How It Works (Without Reverse Engineering)
HTCO promotes directional convergence under high-tension feedback loops. Unlike traditional optimizers that treat every step as equal, HTCO dynamically modulates convergence pressure based on the structural tension detected between parameter vectors and loss surfaces. It does not override the existing optimizer but wraps around it to add a “convergent pull”—a latent mathematical tension field guiding parameters toward smoother valleys. Think of it as a magnetic stabilizer in a turbulent optimization space, adapting its influence as the system evolves. HTCO achieves this via: ⦁ Internal gradient harmonization ⦁ Tension field estimation between parameter states ⦁ Controlled dampening of oscillatory dynamics
Benefits
Stabilizes Chaotic Learning
In high-noise or adversarial settings, HTCO helps your model stay anchored, improving both training reliability and final convergence.
Accelerates Final-Phase Convergence
Near a solution, many optimizers lose precision. HTCO tightens this zone, effectively “pulling” the model into convergence with minimal error spikes.
Modular and Compatible
Works alongside most modern optimizers (Adam, SGD, RMSProp) without requiring internal changes.
Theory-Aligned
Inspired by physical systems, HTCO mimics the behavior of tension minimization in natural systems—bridging AI optimization and physics-based modeling.